As you may or may not have been aware of, a lot of stream processing is going on behind the curtains here at Baqend. In our quest to provide you with the lowest-possible latency, we have not only built a system to enable query caching and real-time notifications (similar to changefeeds in RethinkDB/Horizon) on top of Baqend cloud, but we have also learned a lot about the competition in the field of stream processors. With this article, we want to fill you in on what exactly you can expect from our upcoming real-time features and also want to share our insights on real-time data processing in form of an updated version of our most recent stream processor survey.
With the rise of the web 2.0 and the Internet of things, it has become feasible to track all kinds of information over time, in particular fine-grained user activities and sensor data on their environment and even their biometrics. However, while efficiency remains mandatory for any application trying to cope with huge amounts of data, only part of the potential of today's Big Data repositories can be exploited using traditional batch-oriented approaches as the value of data often decays quickly and high latency becomes unacceptable in some applications. In the last couple of years, several distributed data processing systems have emerged that deviate from the batch-oriented approach and tackle data items as they arrive, thus acknowledging the growing importance of timeliness and velocity in Big Data analytics. In this article, we give an overview over the state of the art of stream processors for low-latency Big Data analytics and conduct a qualitative comparison of the most popular contenders, namely Storm and its abstraction layer Trident, Samza and Spark Streaming. We describe their respective underlying rationales, the guarantees they provide and discuss the trade-offs that come with selecting one of them for a particular task.
Through technological advance and increasing connectivity between people and devices, the amount of data available to (web) companies, governments and other organisations is constantly growing. The shift towards more dynamic and user-generated content in the web and the omnipresence of smart phones, wearables and other mobile devices, in particular, have led to an abundance of information that are only valuable for a short time and therefore have to be processed immediately. Companies like Amazon and Netflix have already adapted and are monitoring user activity to optimise product or video recommendations for the current user context. Twitter performs continuous sentiment analysis to inform users on trending topics as they come up and even Google has parted with batch processing for indexing the web to minimise the latency by which it reflects new and updated sites (see Percolator).
However, the idea of processing data in motion is not new: Complex Event Processing (CEP) engines like Aurora, Borealis or Esper and DBMSs with continuous query capabilities like Tapestry or PipelineDB can provide processing latency on the order of milliseconds and usually expose high-level, SQL-like interfaces and sophisticated querying functionalities like joins. But while typical deployments of these systems do not span more than a few nodes, the systems focused in this article have been designed specifically for deployments with 10s or 100s of nodes. Much like MapReduce, the main achievement of these new systems is abstraction from scaling issues and thus making development, deployment and maintenance of highly scalable systems feasible.
In the following, we provide an overview over some of the most popular distributed stream processing systems currently available and highlight similarities, differences and trade-offs taken in their respective designs. First, we will describe the environment in which the processing systems featured in this article are typically deployed and then we will go into detail on some of them. An overview over other systems for stream processing follows before we describe a use case for stream processing here at Baqend and sum things up.
In contrast to traditional data analytics systems that collect and periodically process huge -- static -- volumes of data, streaming analytics systems avoid putting data at rest and process it as it becomes available, thus minimising the time a single data item spends in the processing pipeline. Systems that routinely achieve latencies of several seconds or even subsecond latency between receiving data and producing output are often described as "real-time". However, large parts of today's Big Data infrastructure are built from distributed components that communicate via asynchronous network and are engineered on top of the JVM (Java Virtual Machine). Thus, these systems are only soft-real-time systems and never provide strict upper bounds on the time they take to produce an output.
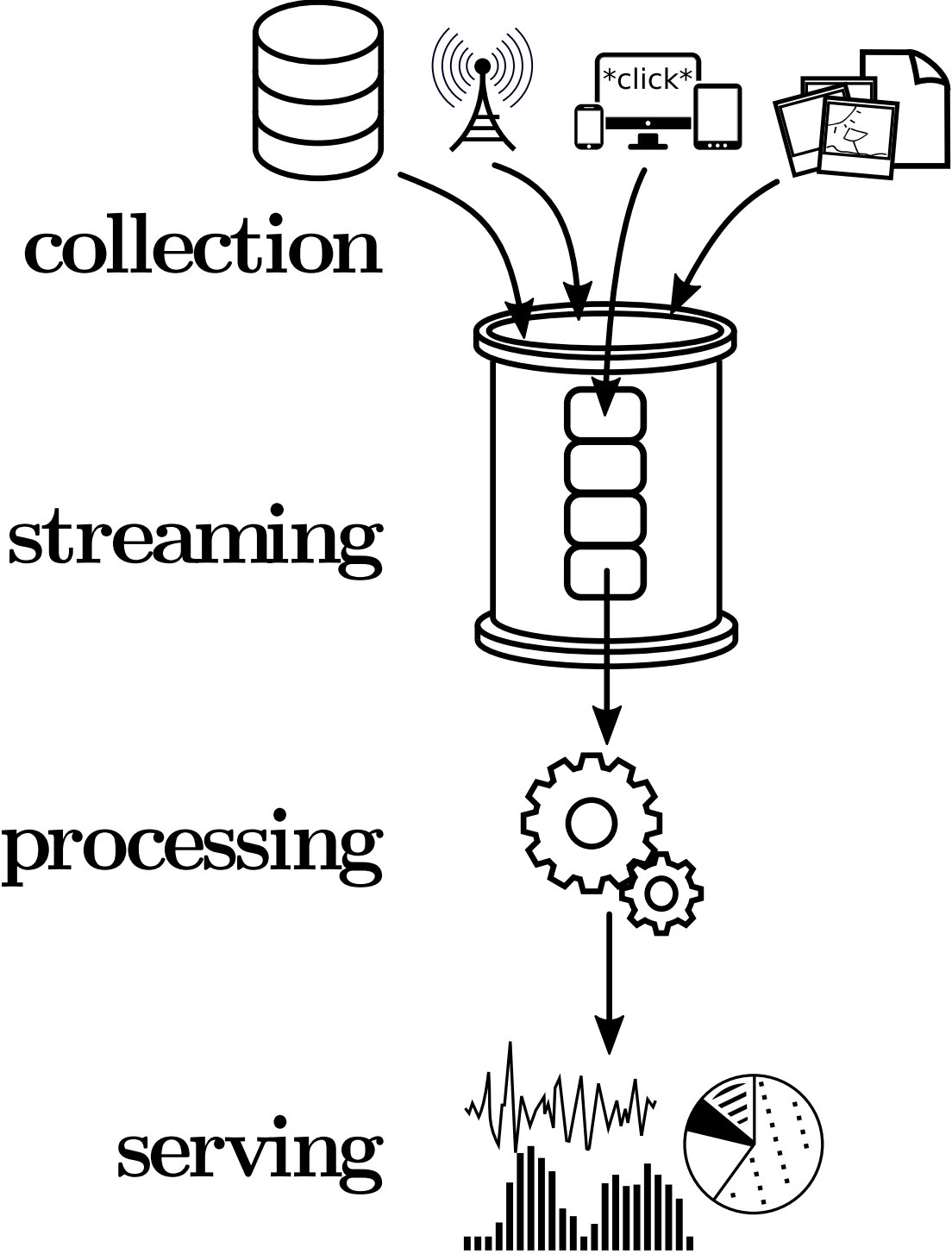
Figure 1 illustrates typical layers of a streaming analytics pipeline. Data like user clicks, billing information or unstructured content such as images or text messages are collected from various places inside an organisation and then moved to the streaming layer (e.g. a queueing system like Kafka, Kinesis or ZeroMQ) from which it is accessible to a stream processor that performs a certain task to produce an output. This output is then forwarded to the serving layer which might for example be an analytics web GUI like trending topics at Twitter or a database where a materialised view is maintained.
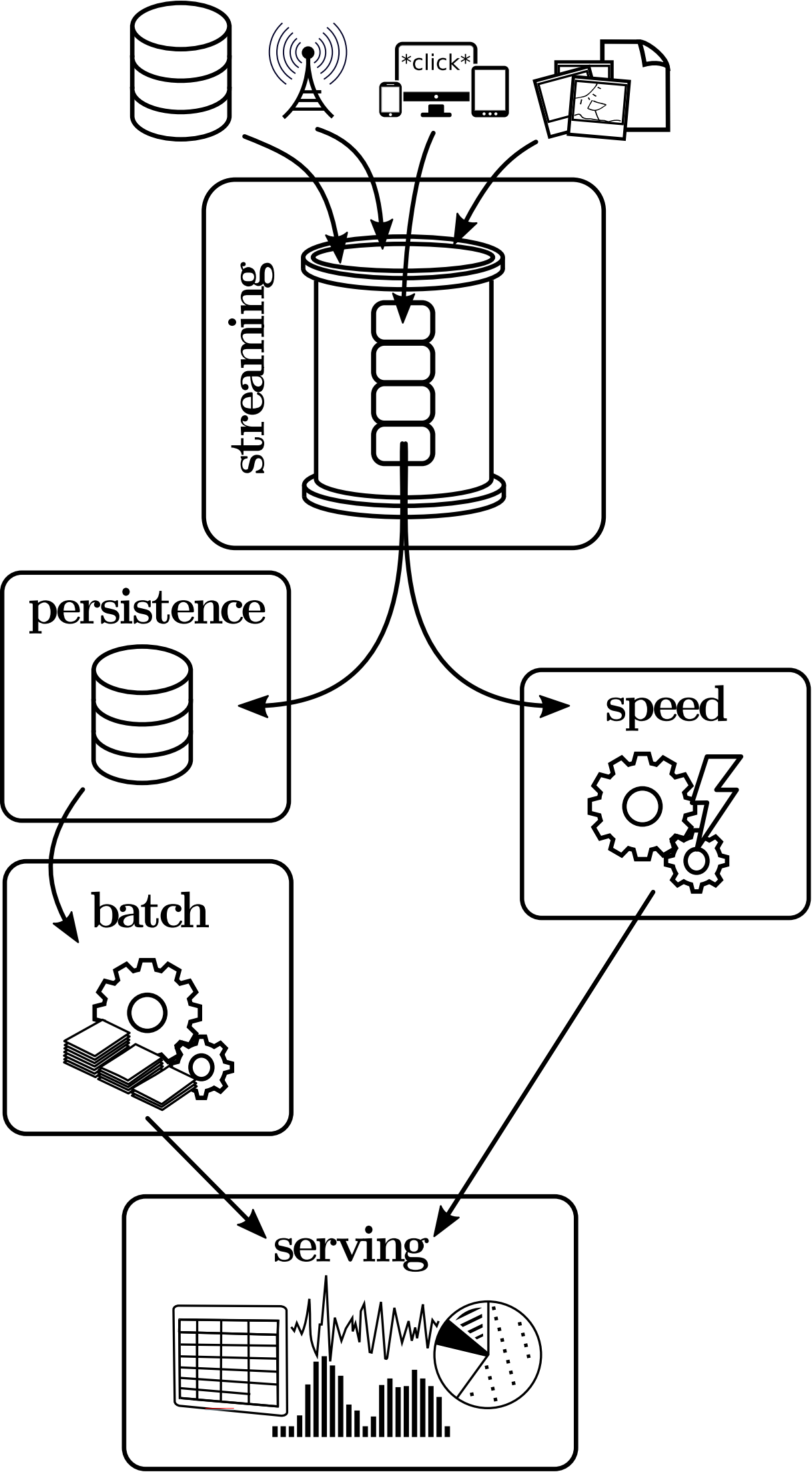
In an attempt to combine the best of both worlds, an architectural pattern called the Lambda Architecture has become quite popular that complements the slow batch-oriented processing with an additional real-time component and thus targets both the Volume and the Velocity challenge of Big Data at the same time. As illustrated in Figure 2, the Lambda Architecture describes a system comprising three layers: Data is stored in a persistence layer like HDFS from which it is ingested and processed by the batch layer periodically (e.g. once a day), while the speed layer handles the portion of the data that has not-yet been processed by the batch layer, and the serving layer consolidates both by merging the output of the batch and the speed layer. The obvious benefit of having a real-time system compensate for the high latency of batch processing is paid for by increased complexity in development, deployment and maintenance. If the batch layer is implemented with a system that supports both batch and stream processing (e.g. Spark), the speed layer often can be implemented with minimal overhead by using the corresponding streaming API (e.g. Spark Streaming) to make use of existing business logic and the existing deployment. For Hadoop-based and other systems that do not provide a streaming API, however, the speed layer is only available as a separate system. Using an abstract language like Summingbird to write the business logic enables automatic compilation of code for both the batch and the stream processing system (e.g. Hadoop and Storm) and thus eases development in those cases where batch and speed layer can use (parts of) the same business logic, but the overhead for deployment and maintenance still remains.
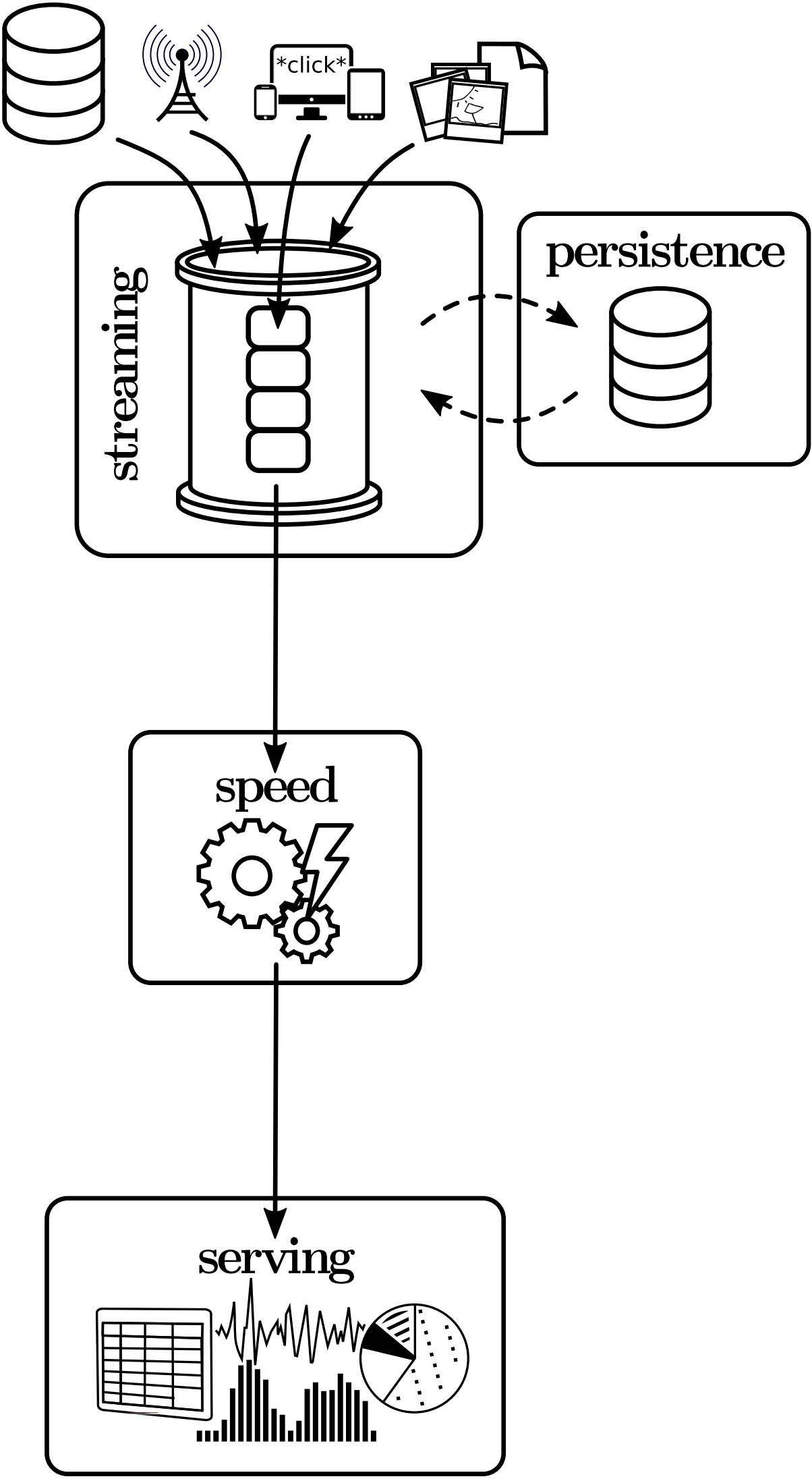
Another approach that, in contrast, dispenses with the batch layer in favor of simplicity is known as the Kappa Architecture and is illustrated in Figure 3. The basic idea is to not periodically recompute all data in the batch layer, but to do all computation in the stream processing system alone and only perform recomputation when the business logic changes by replaying historical data. To achieve this, the Kappa Architecture employs a powerful stream processor capable of coping with data at a far greater rate than it is incoming and a scalable streaming system for data retention. An example of such a streaming system is Kafka which has been specifically designed to work with the stream processor Samza in this kind of architecture. Archiving data (e.g. in HDFS) is still possible, but not part of the critical path and often not required as Kafka, for instance, supports retention times in the order of weeks. On the downside, however, the effort required to replay the entire history increases linearly with data volume and the naive approach of retaining the entire change stream may have significantly greater storage requirements then periodically processing the new data and updating an existing database, depending on whether and how efficiently the data is compacted in the streaming layer. As a consequence, the Kappa Architecture should only be considered an alternative to the Lambda Architecture in applications that do not require unbounded retention times or allow for efficient compaction (e.g. because it is reasonable to only keep the most recent value for each given key).
Of course, the latency displayed by the stream processor (speed layer) alone is only a fraction of the end-to-end application latency due to the impact of the network or other systems in the pipeline. But it is obviously an important factor and may dictate which system to choose in applications with strict timing SLAs. This article concentrates on the available systems for the stream processing layer.
While all stream processors share some common ground regarding their underlying concepts and working principle, an important distinction between the individual systems that directly translates to the achievable speed of processing, i.e. latency, is the processing model as illustrated in Figure 4: Handling data items immediately as they arrive minimises latency at the cost of high per-item overhead (e.g. through messaging), whereas buffering and processing them in batches yields increased efficiency, but obviously increases the time the individual item spends in the data pipeline. Purely stream-oriented systems such as Storm and Samza provide very low latency and relatively high per-item cost, while batch-oriented systems achieve unparalleled resource-efficiency at the expense of latency that is prohibitively high for real-time applications.
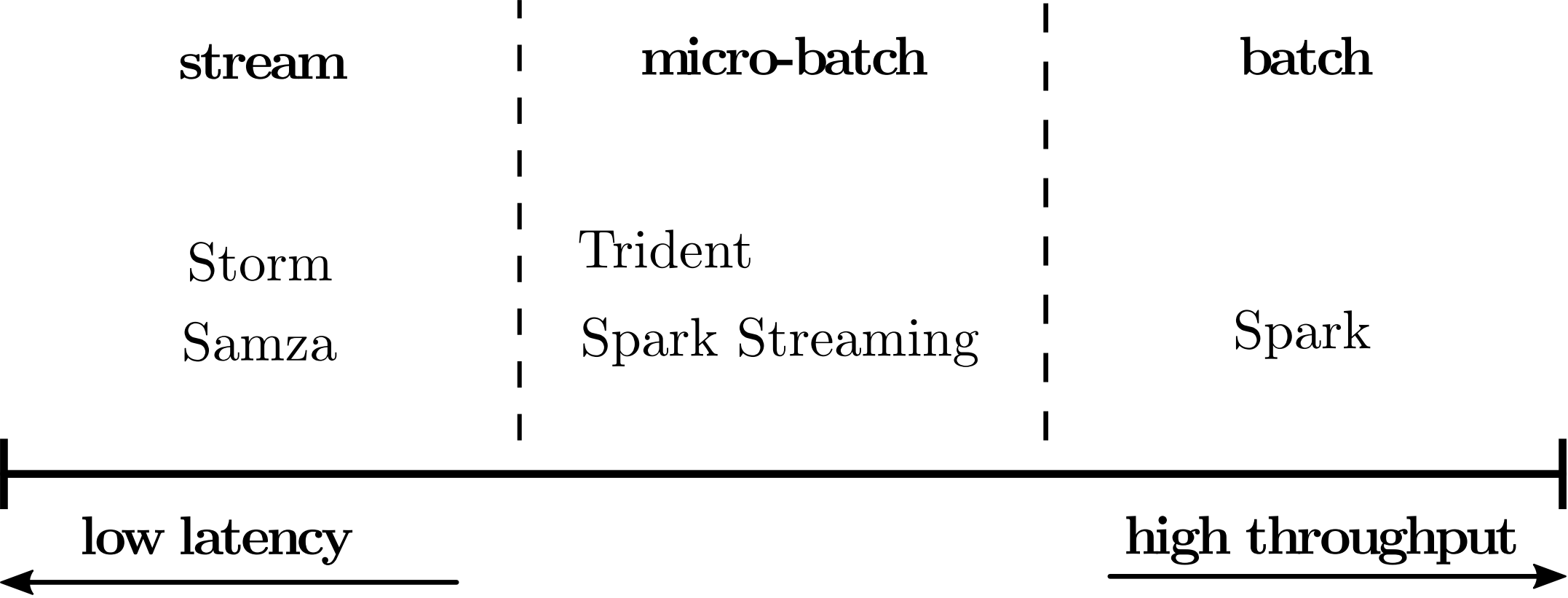
The space between these two extremes is vast and some systems like Storm Trident and Spark Streaming employ micro-batching strategies to trade latency against throughput: Trident groups tuples into batches to relax the one-at-a-time processing model in favor of increased throughput, whereas Spark Streaming restricts batch size in a native batch processor to reduce latency. In the following, we go into more detail on the specificities of the above-mentioned systems and highlight inherent trade-offs and design decisions.
Storm (current stable version: 1.0.3) has been in development since late 2010, was open-sourced in September 2011 by Twitter and eventually became an Apache top-level project in 2014. It is the first distributed stream processing system to gain traction throughout research and practice and was initially promoted as the "Hadoop of real-time", because its programming model provided an abstraction for stream-processing similar to the abstraction that the MapReduce paradigm provides for batch-processing. But apart from being the first of its kind, Storm also has a wide user-base due to its compatibility with virtually any language: On top of the Java API, Storm is also Thrift-compatible and comes with adapters for numerous languages such as Perl, Python and Ruby. Storm can run on top of Mesos, as a dedicated cluster or even on a single machine. The vital parts of a Storm deployment are a ZooKeeper cluster for reliable coordination, several supervisors for execution and a Nimbus server to distribute code across the cluster and take action in case of worker failure; in order to shield against a failing Nimbus server, Storm allows having several hot-standby Nimbus instances. Storm is scalable, fault-tolerant and even elastic as work may be reassigned during runtime. As of version 1.0.0, Storm provides reliable state implementations that survive and recover from supervisor failure. Earlier versions focused on stateless processing and thus required state management at the application level to achieve fault-tolerance and elasticity in stateful applications. Storm excels at speed and thus is able to perform in the realm of single-digit milliseconds in certain applications. Through the impact of network latency and garbage collection, however, real-world topologies usually do not display end-to-end latency consistently below 50 ms.
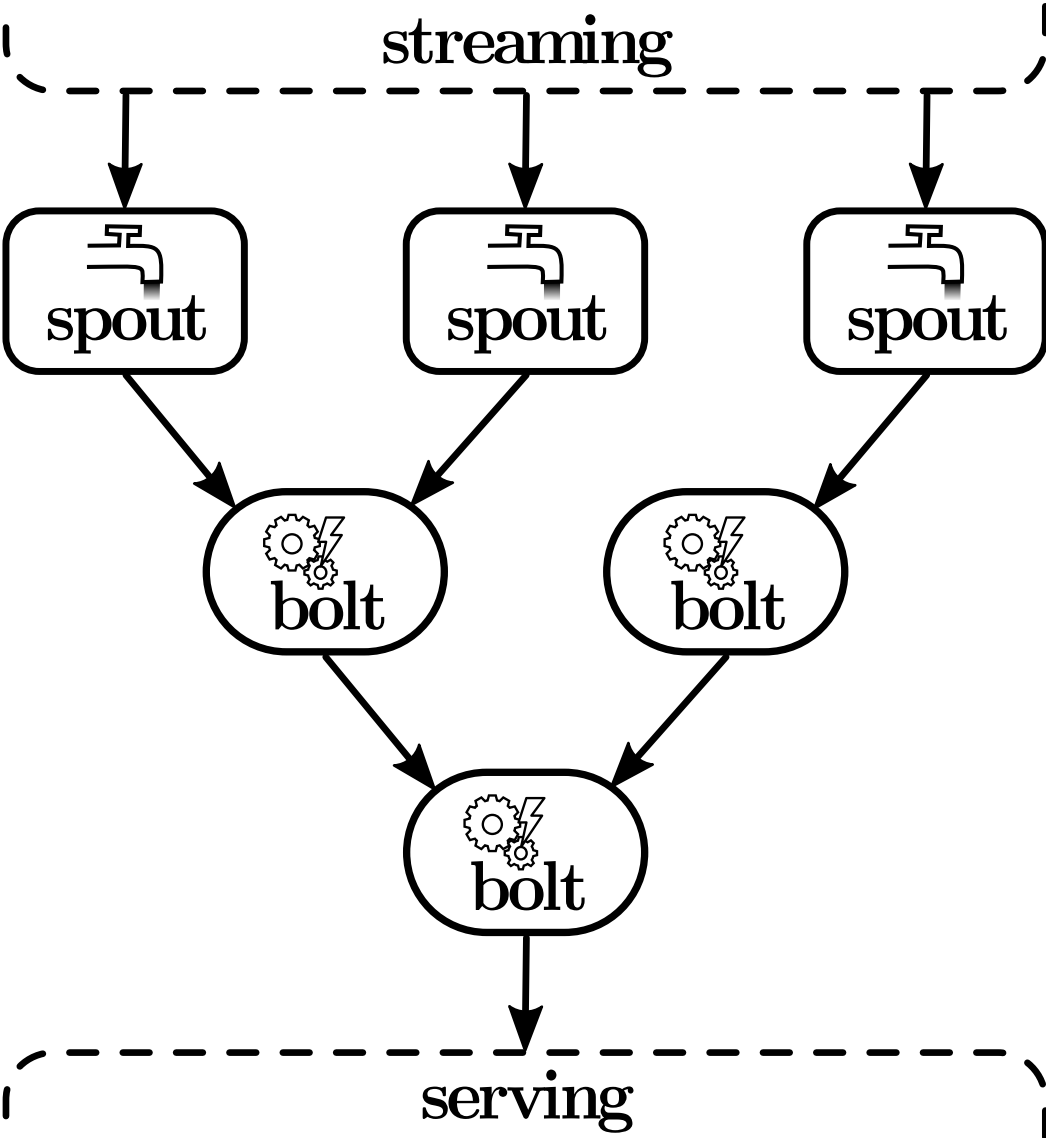
A data pipeline or application in Storm is called a topology and as illustrated in Figure 5 is a directed graph that represents data flow as directed edges between nodes which again represent the individual processing steps: The nodes that ingest data and thus initiate the data flow in the topology are called spouts and emit tuples to the nodes downstream which are called bolts and do processing, write data to external storage and may send tuples further downstream themselves. Storm comes with several groupings that control data flow between nodes, e.g. for shuffling or hash-partitioning a stream of tuples by some attribute value, but also allows arbitrary custom groupings. By default, Storm distributes spouts and bolts across the nodes in the cluster in a round-robin fashion, though the scheduler is pluggable to account for scenarios in which a certain processing step has to be executed on a particular node, for example because of hardware dependencies. The application logic is encapsulated in a manual definition of data flow and the spouts and bolts which implement interfaces to define their behaviour during start-up and on data ingestion or receiving a tuple, respectively.
While Storm does not provide any guarantee on the order in which tuples are processed, it does provide the option of at-least-once processing through an acknowledgement feature that tracks the processing status of every single tuple on its way through the topology: Storm will replay a tuple, if any bolt involved in processing it explicitly signals failure or does not acknowledge successful processing within a given timeframe. Using an appropriate streaming system, it is even possible to shield against spout failures, but the acknowledgement feature is often not used at all in practice, because the messaging overhead imposed by tracking tuple lineage, i.e. a tuple and all the tuples that are emitted on its behalf, noticeably impairs achievable system throughput. With version 1.0.0, Storm introduced a backpressure mechanism to throttle data ingestion as a last resort whenever data is ingested faster than it can be processed. If processing becomes a bottleneck in a topology without such a mechanism, throughput degrades as tuples eventually time-out and are either lost (at-most-once processing) or replayed repeatedly to possibly time-out again (at-least-once processing), thus putting even more load on an already overburdened system.
In autumn 2012 and version 0.8.0, Trident was released as a high-level API with stronger ordering guarantees and a more abstract programming interface with built-in support for joins, aggregations, grouping, functions and filters. In contrast to Storm, Trident topologies are directed acyclic graphs (DAGs) as they do not support cycles; this makes them less suitable for implementing iterative algorithms and is also a difference to plain Storm topologies which are often wrongfully described as DAGs, but actually can introduce cycles. Also, Trident does not work on individual tuples, but on micro-batches and correspondingly introduces batch size as a parameter to increase throughput at the cost of latency which, however, may still be as low as several milliseconds for small batches. All batches are by default processed in sequential order, one after another, although Trident can also be configured to process multiple batches in parallel. On top of Storm's scalability and elasticity, Trident provides its own API for fault-tolerant state management with exactly-once processing semantics. In more detail, Trident prevents data loss by using Storm's acknowledgement feature and guarantees that every tuple is reflected only once in persistent state by maintaining additional information alongside state and by applying updates transactionally. As of writing, two variants of state management are available: One only stores the sequence number of the last-processed batch together with current state, but may block the entire topology when one or more tuples of a failed batch cannot be replayed (e.g. due to unavailability of the data source), whereas the other can tolerate this kind of failure, but is more heavyweight as it also stores the last-known state. Irrespective of whether batches are processed in parallel or one by one, state updates have to be persisted in strict order to guarantee correct semantics. As a consequence, their size and frequency can become a bottleneck and Trident can therefore only feasibly manage small state.
Samza (current stable version: 0.10.1) is very similar to Storm in that it is a stream processor with a one-at-a-time processing model and at-least-once processing semantics. It was initially created at LinkedIn, submitted to the Apache Incubator in July 2013 and was granted top-level status in 2015. Samza was co-developed with the queueing system Kafka and therefore relies on the same messaging semantics: Streams are partitioned and messages (i.e. data items) inside the same partition are ordered, whereas there is no order between messages of different partitions. Even though Samza can work with other queueing systems, Kafka's capabilities are effectively required to use Samza to its full potential and therefore it is assumed to be deployed with Samza for the rest of this section. (As a side note, Kafka has been featuring its own Samza-like stream processing library, Kafka Streams, since May 2016.) In comparison to Storm, Samza requires a little more work to deploy as it does not only depend on a ZooKeeper cluster, but also runs on top of Hadoop YARN for fault-tolerance: In essence, application logic is implemented as a job that is submitted through the Samza YARN client which has YARN then start and supervise one or more containers. Scalability is achieved through running a Samza job in several parallel tasks each of which consumes a separate Kafka partition; the degree of parallelism, i.e. the number of tasks, cannot be increased dynamically at runtime. Similar to Kafka, Samza focuses on support for JVM-languages, particularly Java. Contrasting Storm and Trident, Samza is designed to handle large amounts of state in a fault-tolerant fashion by persisting state in a local database and replicating state updates to Kafka. By default, Samza employs a key-value store for this purpose, but other storage engines with richer querying capabilities can be plugged in.
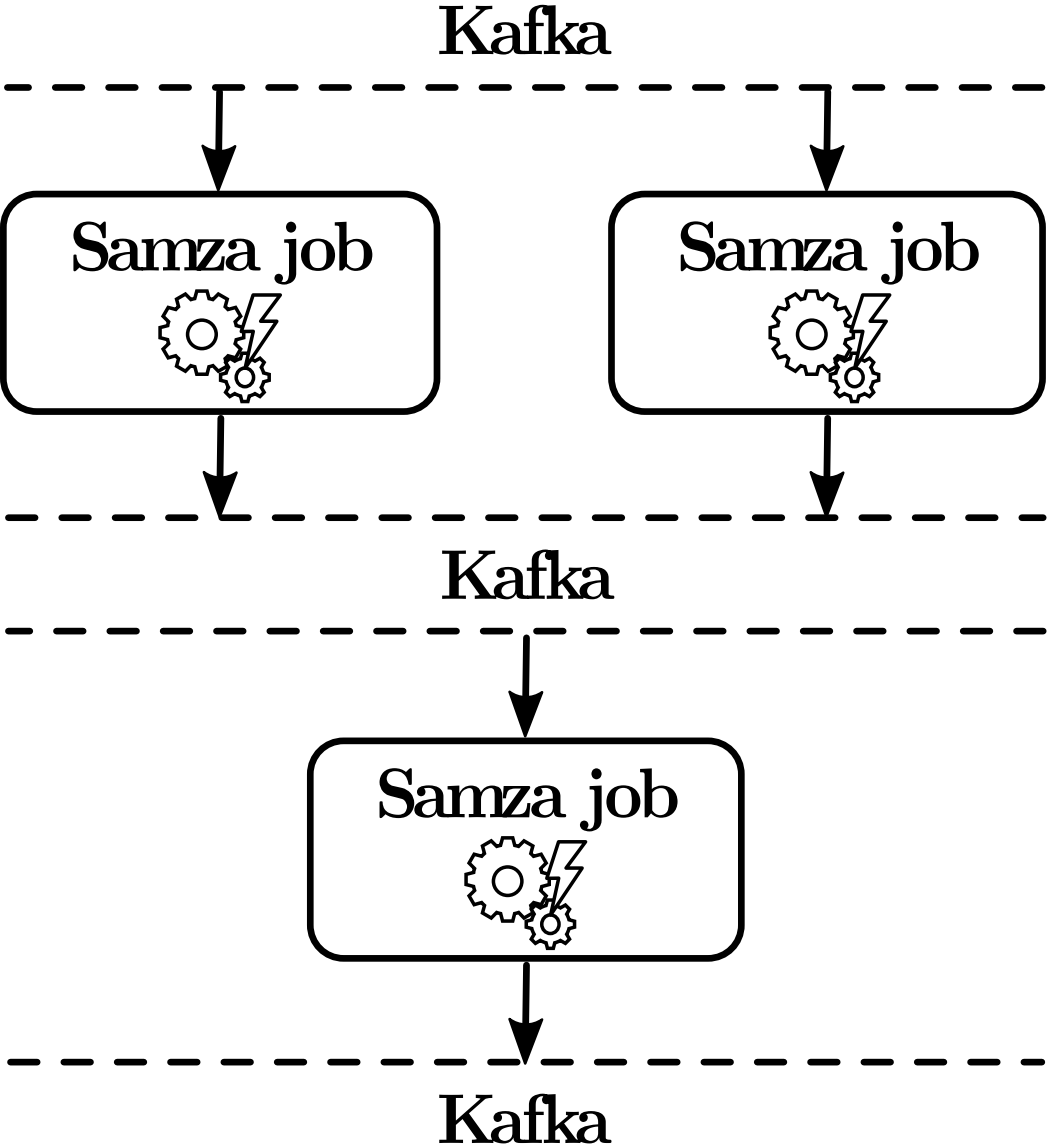
As illustrated in Figure 6, a Samza job represents one processing step in an analytics pipeline and thus roughly corresponds to a bolt in a Storm topology. In stark contrast to Storm, however, where data is directly sent from one bolt to another, output produced by a Samza job is always written back to Kafka from where it can be consumed by other Samza jobs. Although a single Samza job or a single Kafka persistence hop may delay a message by only a few milliseconds, latency adds up and complex analytics pipelines comprising several processing steps eventually display higher end-to-end latency than comparable Storm implementations.
However, this design also decouples individual processing steps and thus eases development. Another advantage is that buffering data between processing steps makes (intermediate) results available to unrelated parties, e.g. other teams in the same company, and further eliminates the need for a backpressure algorithm, since there is no harm in the backlog of a particular job filling up temporarily, given a reasonably sized Kafka deployment. Since Samza processes messages in order and stores processing results durable after each step, it is able to prevent data loss by periodically checkpointing current progress and reprocessing all data from that point onwards in case of failure; in fact, Samza does not support a weaker guarantee than at-least-once processing, since there would be virtually no performance gain in relaxing this guarantee. While Samza does not provide exactly-once semantics, it allows configuring the checkpointing interval and thus offers some control over the amount of data that may be processed multiple times in an error scenario.
The Spark framework (current stable version: 2.0.0) is a batch-processing framework that is often mentioned as the inofficial successor of Hadoop as it offers several benefits in comparison, most notably a more concise API resulting in less verbose application logic and significant performance improvements through in-memory caching: In particular, iterative algorithms (e.g. machine learning algorithms such as k-means clustering or logistic regression) are accelerated by orders of magnitude, because data is not necessarily written to and loaded from disk between every processing step. In addition to these performance benefits, Spark provides limited SQL support and a variety of machine learning algorithms out-of-the-box through the MLlib library. Originating from UC Berkeley in 2009, Spark was open-sourced in 2010 and was donated to the Apache Software Foundation in 2013 where it became a top-level project in February 2014. It is mostly written in Scala and has a Java, Scala and Python API. The core abstraction of Spark are distributed and immutable collections called RDDs (resilient distributed datasets) that can only be manipulated through deterministic operations. Spark is resilient to machine failures by keeping track of any RDD's lineage, i.e. the sequence of operations that created it, and checkpointing RDDs that are expensive to recompute, e.g. to HDFS. A Spark deployment consists of a cluster manager for resource management (and supervision), a driver program for application scheduling and several worker nodes to execute the application logic. Spark runs on top of Mesos, YARN or in standalone mode in which case it may be used in combination with ZooKeeper to remove the master node, i.e. the cluster manager, as a single point of failure.
Spark Streaming shifts Spark's batch-processing approach towards real-time requirements by chunking the stream of incoming data items into small batches, transforming them into RDDs and processing them as usual. It further takes care of data flow and distribution automatically. Spark Streaming has been in development since late 2011 and became part of Spark in February 2013. Being a part of the Spark framework, Spark Streaming had a large developer community and also a huge group of potential users from day one, since both systems share the same API and since Spark Streaming runs on top of a common Spark cluster. Thus, it can be made resilient to failure of any component like Storm and Samza and further supports dynamically scaling the resources allocated for an application. Data is ingested and transformed into a sequence of RDDs which is called DStream (discretised stream) before processing through workers. All RDDs in a DStream are processed in order, whereas data items inside an RDD are processed in parallel without any ordering guarantees. Since there is a certain job scheduling delay when processing an RDD, batch sizes below 50 ms tend to be infeasible. Accordingly, processing an RDD takes around 100 ms in the best case, although Spark Streaming is designed for latency in the order of a few seconds (see Spark Streaming paper, Section 2). To prevent data loss even for unreliable data sources, Spark Streaming grants the option of using a write-ahead log (WAL) from which data can be replayed after failure. State management is realised through a state DStream that can be updated through a DStream transformation.
Flink (current stable version: 1.1.2) is a project that has many parallels to Spark Streaming as it also originated from research and advertises the unification of batch and stream processing in the same system, providing exactly-once guarantees for the stream programming model and a high-level API comparable to that of Trident. Formerly known as Stratosphere, Flink has been going by its current name since mid-2014 and reached stable version 1.0.0 in March 2016. In contrast to Spark Streaming, Flink is a native stream processor and does not rely on batching internally. Apart from the batching API and the streaming API in the focus of this article, Flink also provides APIs for graph processing, complex event processing and SQL and an executer to run storm topologies, possibly even with exactly-once state management in a future release (see slide 30). Flink can be deployed using a resource negotiators such as YARN or Mesos, but also in standalone-mode directly on machines. A Flink deployment has at least one job manager process (with optional standbys for failover) to coordinate checkpointing, recovery and to receive Flink jobs. The job manager also schedules work across the task manager processes which usually reside on separate machines and in turn execute the code. Resource allocation for a job is currently static, but dynamic scaling is a planned feature.
Conceptually, Flink can be considered one of the more advanced stream processors as many of its core features were already considered in the initial design and not just added as an afterthought as opposed to Spark's streaming API or state management in Storm, for instance. However, only relatively few big players have committed to using it in production so far. To provide exactly-once processing guarantees, Flink uses an algorithm grounded in the Chandy-Lamport algorithm for distributed snapshots: Essentially, watermark items are periodically injected into the data streams and trigger any receiving component to create a checkpoint of its local state. On success, the entirety of all local checkpoints is the distributed global system checkpoint. In a failure scenario, all components are reset to the last valid global checkpoint and data is replayed from the corresponding watermark. Since data items may never overtake watermark items (which are therefore also called barriers), acknowledgment does not happen on a per-item basis and is consequently much more lightweight than in Storm. Flink implements a back pressure mechanism through buffers with bounded capacity: Whenever ingestion is overtaking processing speed, the data buffers effectively behave like fixed-size blocking queues and thus slow down the rate at which new data enters the system. By making the buffering time for data items configurable, Flink promotes an explicit trade-off between latency and throughput and can sustain higher throughput than Storm. But while Flink is able to provide consistent latency well below 100 ms, it cannot satisfy as aggressive latency goals as Storm.
| Storm | Trident | Samza | Spark Streaming | Flink (streaming) | |
| strictest guarantee | at-least-once | exactly-once | at-least-once | exactly-once | exactly-once |
| achievable latency | ≪100 ms | <100 ms | <100 ms | < 1 second | <100 ms |
| state management | yes | yes (small state) | yes | yes | yes |
| processing model | one-at-a-time | micro-batch | one-at-a-time | micro-batch | one-at-a-time |
| backpressure mechanism | yes | yes | not required (buffering) | yes | yes |
| ordering guarantees | no | between batches | within stream partitions | between batches | within stream partitions |
| elasticity | yes | yes | no | yes | no |
Table 1 sums up the properties of the discussed systems in direct comparison. Storm provides the lowest latency, but does not offer ordering guarantees and is often deployed providing no delivery guarantees at all, since the per-tuple acknowledgement required for at-least-once processing effectively doubles messaging overhead. Stateful exactly-once processing is available in Trident through idempotent state updates, but has notable impact on performance and even fault-tolerance in some failure scenarios. Samza is another native stream processor that has not been geared towards low latency as much as Storm and puts more focus on providing rich semantics, in particular through a built-in concept of state management. Having been developed for use with Kafka in the Kappa Architecture, Samza and Kafka are tightly integrated and share messaging semantics; thus, Samza can fully exploit the ordering guarantees provided by Kafka. Spark Streaming and Flink effectively bring together batch and stream processing (even though from different directions) and offer high-level APIs, exactly-once processing guarantees and a rich set of libraries, all of which can greatly reduce the complexity of application development. The Spark ecosystem undoubtedly has the largest user and developer base, but being a native batch processor, Spark Streaming loses to its contenders with respect to latency. Flink does not inherit serious limitations from its design, but is not as widely adopted, yet.
All these different systems show that low latency is involved in a number of trade-offs with other desirable properties such as throughput, fault-tolerance, reliability (processing guarantees) and ease of development. Throughput can be optimised by buffering data and processing it in batches to reduce the impact of messaging and other overhead per data item, whereas this obviously increases the in-flight time of individual data items. Abstract interfaces hide system complexity and ease the process of application development, but sometimes also limit the possibilities of performance tuning. Similarly, rich processing guarantees and fault-tolerance for stateful operations increase reliability and make it easier to reason about semantics, but require the system to do additional work, e.g. acknowledgements and (synchronous) state replication. Exactly-once semantics are particularly desirable and can be implemented through combining at-least-once guarantees with either transactional or idempotent state updates, but they cannot be achieved for actions with side-effects such as sending a notification to an administrator.
In the last couple of years, a great number of stream processors have emerged that all aim to provide high availability, fault-tolerance and horizontal scalability. Project Apex is the open-sourced DataTorrent RTS core engine. Much like Flink, Apex promises high performance in stream and batch processing with low latency in streaming workloads. As Spark/Spark Streaming, Flink and Apex are complemented by a host of database, file system and other connectors as well as pattern matching, machine learning and other algorithms through additional libraries. A system that is not publicly available is Twitter's Heron. Designed to replace Storm at twitter, Heron is completely API-compatible to Storm, but improves on several aspects such as backpressure, efficiency, resource isolation, multitenancy, ease of debugging and performance monitoring, but reportedly does not provide exactly-once delivery guarantees. MillWheel is an extremely scalable stream processor that offers similar qualities as Flink and Apex, e.g. state management and exactly-once semantics. Millwheel and FlumeJava are the execution engines behind Google's Dataflow cloud service for data processing. Like other Google services and unlike most other systems discussed in this section, Dataflow is fully managed and thus relieves its users of the burden of deployment and all related troubles. The Dataflow programming model combines batch and stream processing and is also agnostic of the underlying processing system, thus decoupling business logic from the actual implementation. The runtime-agnostic API was open-sourced in 2015 and has evolved into the Apache Beam project (short for Batch and stream, currently incubating) to bundle it with the corresponding execution engines (runners): As of writing, Flink, Spark and the proprietary Google Dataflow cloud service are supported. The only other fully managed stream processing system apart from Google Dataflow that we are aware of is IBM Infosphere Streams. However, in contrast to Google Dataflow which is documented to be highly scalable, it is hard to find evidence for high scalability of IBM Infosphere Streams; performance evaluations made by IBM only indicate it performs well in small deployments with up to a few nodes. Flume is a system for efficient data aggregation and collection that is often used for data ingestion into Hadoop as it integrates well with HDFS and can handle large volumes of incoming data. But Flume also supports simple operations such as filtering or modifying on incoming data through Flume Interceptors which may be chained together to form a low-latency processing pipeline. The list of distributed stream processors goes on (see for example Muppet, S4, Photon, Sonora or other Apache stream processors), but since a complete discussion of the Big Data stream processing landscape is out of the scope of this article, we do not go into further detail here.
Maybe a little more text on how exactly we are using Storm.
Batch-oriented systems have done the heavy lifting in data-intensive applications for decades, but they do not reflect the unbounded and continuous nature of data as it is produced in many real-world applications. Stream-oriented systems, on the other hand, process data as it arrives and thus are oftentimes a more natural fit, though inferior with respect to efficiency. While a growing number of production deployments implementing the Lambda Architecture and emerging hybrid systems like Dataflow/Beam, Flink or Apex document significant efforts to close the gap between batch and stream--processing in both research and practice, the Kappa Architecture completely eschews the traditional approach and even heralds the advent of purely stream-oriented Big Data analytics. However, whether at the core of novel system designs or as a complement to existing architectures, horizontally scalable stream processors are gaining momentum as the requirement for low latency has become a driving force in modern Big Data analytics pipelines.